Machine Learning Questions

In here we will ask and answer many machine learning questions.
Table of Contents:
- 1. Who created the first mathematical model of the neural network?
- 2. The Turing test of intelligence is designed for?
- 3. Basic structural element of a neural network is called?
- 4. Expert system is an artificial intelligence (Ai) program that has expert knowledge on a specific topic and knows how to utilize that.
- 5. Deep learning is part of machine learning.
- 6. An easy way to learn and use TensorFlow is called:
- 7. All the neuron weights inside a neural network system are also called:
- 8. A practical solution to a problem that assumes learning, testing and probing is commonly called:
- 9. Both Python and R programming languages are great for programming Ai solutions?
- 10. Feed-forward neural networks (FFNN) are networks where the connections between the neurons do not form a cycle?
- 11. Feed-forward neural networks can be used to approximate continuous functions.
- 12. The purpose of the activation function is to introduce non-linearity into the network.
- 13. Should the activation function be differentiable?
- 14. Machine learning practitioners are always afraid of:
- 15. You haven’t trained your neural network. Can you still expect it will work correctly?
- 16. Should we train our neural network systems using both train and test data?
- 17. What are TensorFlow and PyTorch?
- 18. ReLU is probably the most used?
- 19. Typically every neural network layer uses a single activation function.
- 20. You need to detect spam. What learning model would you use?
- 21. Find the intruder:
- 22. Support vector machine (SVM) systems can be used for both classification and regression analysis?
- 23. You use the Hinge loss function to calculate the error. What kind of a model are you most likely having?
- 24. A multilayer perceptron (MLP) and support vector machines (SVM) systems use the same principles beneath?
- 25. Find the wrong type of regression?
- 26. How can you reduce the input dimensionality of a NN?
- 27. Convolutional Neural Networks, Deep Belief Networks, Deep Auto-Encoders, Recurrent Neural Networks, Generative Adversarial Networks are:
- 28. To recognize images you would typically use?
- 29. Name the loss function that leads to better probability estimation:
- 30. The softmax function, takes N-dimensional vector or arbitrary real values and returns:
- 31. Find the intruder?
- 32. Which method is not used to suppress overfitting?
- 33. Regularization will make your model:
- 34. Convolution filters reduce memory needed to train the model?
- 35. Those are parameters that are used to configure a convolution layer. Which one is used to set how many pixels the kernel windows will slide.
- 36. Hidden Markov Model (HMMs) is used often for?
- 37. Your targets are one-hot encoded. Which loss function would you choose?
- 38. What is an agent in artificial intelligence?
- 39. We update the weights of our NN directly based on the:
- 40. What is the name of the object in Google TensorFlow that encapsulates the environment in which operation objects are executed?
- 41. Keras is an open source neural network library written in?
- 42. What does Keras mean?
- 43. Pandas is a column-oriented data analysis API. The primary data structures in pandas are DataFrame and Series. Which one represents a column?
- 44. In TensorFlow using tf.estimator dramatically lowers the number of lines of code?
- 45. When Ai system performs as high-human this means it performs:
- 46. What is R-CNN?
- 47. Generative adversarial networks (GANs) are close to something called “machine dreaming “?
- 48. Which one is fastest NN recognizing 2D objects regions?
- 49. Can AI create music?
- 50. Find the intruder:
- Additional material
- Logistic regression?
- What is information?
1. Who created the first mathematical model of the neural network?
1) Claude Shannon 2) Alan Turing 3) Thomas Bayes 4) Walter Pitts and Warren McCulloch
According to Wikipedia Walter Pitts, a logician, and Warren McCulloch, a neuroscientist, gave the first mathematical model of a neural network in 1943. They proposed a way to mimic the human neuron.
Their model called McCulloch-Pitts neuron is still referenced today although it evolved over the years as the one in the image.
2. The Turing test of intelligence is designed for?
1) humans 2) machines
The Turing test (by Alan Turing) is something machines should solve. It is a test of a machine’s ability to exhibit intelligent behavior indistinguishable from a human.
In order to pass the test, machines should have the ability to recognize speech, think and speak like a human.
3. Basic structural element of a neural network is called?
1) The perceptron 2) The neuron 3) both are ok
The perceptron was the original name for the neuron given in 1960 by Frank Rosenblatt. However, the term neuron is used more often today.
4. Expert system is an artificial intelligence (Ai) program that has expert knowledge on a specific topic and knows how to utilize that.
1) True 2) False
Thanks to machine learning (ML) machines can learn and substitute human experts.
Note: Expert systems may not be based on machine learning. They may be programmed as a set of if–then rules to emulate the the decision-making ability of a human expert. This is how the original expert systems came to light.
5. Deep learning is part of machine learning.
1) True 2) False
Deep learning is part of machine learning, part artificial intelligence, part of science.
6. An easy way to learn and use TensorFlow is called:
1) Github 2) Colaboratory
Colaboratory (Colab) is a tool for machine learning education and research. It’s a Jupyter notebook environment that requires no setup and it works from a web browser.
Colab notebooks are just like Google Docs and Sheets. In Colab TensorFlow is already pre-installed.
7. All the neuron weights inside a neural network system are also called:
1) tensors 2) activations 3) parameters 4) hyperparameters
Neuron weights are commonly called parameters.
Hyperparameters are higher-level properties of a model such as how fast it can learn (learning rate) or they define the complexity of a model. For instance, the number of hidden layers in NN may be a hyperparameter.
Tensors are N-dimensional arrays representing N-dimensional space.
Activities are values we feed the network layer.
8. A practical solution to a problem that assumes learning, testing and probing is commonly called:
1) algorithm 2) heuristic
An algorithm is a clearly defined set of instructions to solve the problem, while heuristics involves learning and discovery to reach a goal.
When we know exactly how to solve a problem we create the algorithm.
When we try and test in order to reach the goal we are using heuristic. Heuristic solution may not be optimal, nor logical, nor rational, but it should be sufficient for reaching the goal.
9. Both Python and R programming languages are great for programming Ai solutions?
1) True 2) False
Python is considered to be in the first place in the list of all Ai development languages because it is simple and has great libraries such as numpy and scikit-learn, and it is used in Tensorflow and PyTorch.
R has numerous packages like RODBC, Gmodels, Class and Tm which are used in the field of machine learning. These packages make the implementation of machine learning algorithms easy, for cracking the business associated problems.
10. Feed-forward neural networks (FFNN) are networks where the connections between the neurons do not form a cycle?
1) True 2) False
Inside feed-forward neural networks the connections between the nodes do not form a cycle. The feed-forward neural network was the first and simplest type of artificial neural network discovered.
This is opposite to recurrent neural networks (RNN).
11. Feed-forward neural networks can be used to approximate continuous functions.
1) True 2) False
In the theory of artificial neural networks, the universal approximation theorem states that a feed-forward network with just a single hidden layer containing a finite number of neurons can approximate continuous functions of n-dimensional Euclidean space.
The proofs of the universal approximation theorem exist for the sigmoidal activation function, but it is possible to make proofs for other activation functions.
12. The purpose of the activation function is to introduce non-linearity into the network.
1) True 2) False
A neural network without the activation function would simply be a linear regression model, which has limited power and does not perform well with a small number of nodes.
13. Should the activation function be differentiable?
1) True 2) False
We need the activation function to be differentiable to effectively learn the neuron weights using the backpropagation algorithm.
14. Machine learning practitioners are always afraid of:
1) overfitting 2) gradient descent 3) gradient ascent
Overfitting means that your model predicts well on the data that you used to train, but performs poorly on new data it hasn’t seen before.
Overfitting can happen if one parameter dominates the formula. Regularization is a process added inline with the optimization function to avoid overfitting.
15. You haven’t trained your neural network. Can you still expect it will work correctly?
1) Yes, because some neural networks may not be trained. 2) No, all neural networks should be trained
The neural networks should be trained first to reach the level of accuracy we plan.
16. Should we train our neural network systems using both train and test data?
1) YES 2) NO
Never train your neural network on test data. If you are seeing surprisingly good results on your evaluation metrics, it might accidentally train your system on a test dataset.
Experts agree 80% of the overall data should be used to train, and 20% of the overall data should be used to test the network.
17. What are TensorFlow and PyTorch?
1) machine learning frameworks 2) matlab extensions
These are popular open source machine learning frameworks.
TensorFlow developed by the Google Brain team is an open-source software written in C++ and Python.
PyTorch is an open source machine learning library for Python, based on Torch, used for applications such as natural language processing. It is primarily developed by Facebook’s artificial-intelligence research group.
18. ReLU is probably the most used?
1) activation function 2) loss function 3) cost function
ReLU (Rectified Linear Unit) is probably the most used activation function in NN. This function is simple.
It is $0$ when $x<=0$ and identity $f(x)=x$ when $x>0$.
The other activation functions you may use are: sigmoid, identity, binary step, logistic, sinusoid, tanh, arctan.
19. Typically every neural network layer uses a single activation function.
1) True 2) False
Although it is possible not to do so, activation functions are almost always set for the whole layer. Different layers may use different activation functions.
20. You need to detect spam. What learning model would you use?
1) a regression model 2) a classification model
A classification model predicts discrete values. For example, classification models make predictions if the image represents a dog, a cat, or a tiger.
A regression model predicts continuous values. For example, regression models make predictions like what is the price of a car taking many different factors in.
21. Find the intruder:
1) regression 2) classification 3) clustering
Regression and classification analysis are supervised machine learning techniques in general.
Clustering is an unsupervised learning approach together with association.
Regression predicts continuous values for the output. Predicting a person’s income from their age and education is an example of a regression task.
Classification predicts a discrete number of values. In classification the data is categorized under different labels according to some parameters and then the labels are predicted for the data. Detecting email spam is an example of the classification problem.
Clustering grouping the data based on similarities data may have.
22. Support vector machine (SVM) systems can be used for both classification and regression analysis?
1) True 2) False
Support vector machine (SVM) system refers to a set of related supervised learning methods that analyze data and recognize patterns, used for classification and regression analysis.
SVM and NN work a bit differently. After using the kernel trick, SVMs are equivalent to FFNN with a non-linear activation function.
The kernel trick means transforming data into another dimension that has a clear dividing margin between classes of data.
23. You use the Hinge loss function to calculate the error. What kind of a model are you most likely having?
1) classification 2) regression
In machine learning, the Hinge loss function is used for training classifiers.
The Hinge loss is used for maximum margin classification.
24. A multilayer perceptron (MLP) and support vector machines (SVM) systems use the same principles beneath?
1) True 2) False
MLP and SVM principles differ.
A multilayer perceptron (MLP) is a feed-forward artificial neural network type. MLP consists of, at least, three layers of nodes: an input layer, a hidden layer and an output layer.
Except for the input nodes, each node is a neuron that uses a nonlinear activation function. MLP utilizes a supervised learning technique called backpropagation while training.
Support vector machines (SVM) is a supervised machine learning algorithm which can be used for classification or regression problems. It uses a technique called “the kernel trick” to transform the space system. Training process assumes things like changing the kernel, gamma and C value.
25. Find the wrong type of regression?
1) logistic regression 2) binary regression 3) polynomial regression
Regression is the common machine learning model, estimating the relationships between variables.
There are several types of regressions: Linear Regression, Logistic Regression, Polynomial Regression, Stepwise Regression, Ridge Regression, Lasso Regression, etc.
Use the logistic function to model binary dependent variables. Binary regression as a term is not used.
26. How can you reduce the input dimensionality of a NN?
1) PCA 2) Isomap 3) LLE 4) SVD 5) all mentioned
PCA, LLE, ISOMAP, and other methods like SOM can be used to reduce the input image dimension to a NN. This is very important in order to decrease the NN input data.
Principal Component Analysis (PCA) is a linear mathematical technique to reduce the dimensionality of data. It uses a linear mapping of the data to a lower-dimensional space in such a way that the variance of the data in the low-dimensional representation is maximized. PCA uses the SVD (singular value decomposition) technique.
Locally Linear Embedding (LLE) attempts to discover nonlinear structure in high dimensional data by exploiting the local symmetries of linear reconstructions.
Isomap is a nonlinear dimensionality reduction method. It is highly efficient and generally applicable to a broad range of data sources and dimensionalities.
Self Organizing Maps (SOM) is a multi-dimensional scaling technique which constructs an approximation of the probability density function of some underlying data set X which also preserves the topological structure of that data set.
27. Convolutional Neural Networks, Deep Belief Networks, Deep Auto-Encoders, Recurrent Neural Networks, Generative Adversarial Networks are:
1) Deep NN 2) Shallow NN
Shallow neural networks is a term used to describe NN that usually have only one hidden layer as opposed to deep NN which have several hidden layers, often of various types.
28. To recognize images you would typically use?
1) CNN 2) BBC 3) NBC
Convolutional Neural Networks (CNN) gained a lot of momentum over the last few years, especially in the field of image recognition.
BBC and NBC are not Ai acronyms yet.
29. Name the loss function that leads to better probability estimation:
1) Logarithmic loss 2) Hinge loss
Logarithmic loss leads to better probability estimation compared to the Hinge loss function.
Hinge loss leads to better accuracy and some sparsity at the cost of much less sensitivity regarding probabilities.
30. The softmax function, takes N-dimensional vector or arbitrary real values and returns:
1) N-dimensional vector of real values 2) a scalar
Softmax returns a N-dimensional vector of real values where the sum of all values at the output equals 1.
In other words, softmax returns probabilities, especially maximizing just one.
31. Find the intruder?
1) Adagrad 2) madam 3) Adam 4) Eve
Here Adam, Adagrad, and Eve are famous optimizers based on gradient descent and the name madam is not connected with any optimizar function.
During the training process, the weights of the NN model are altered in order to minimize the loss function. Optimizers help us minimize the loss effectively.
Adagrad adapts the learning rate specifically to individual features: that means that some of the weights in your dataset will have different learning rates compared to other weights. This works really well for sparse datasets where a lot of input examples are missing. Adagrad has a major issue though: the adaptive learning rate tends to get really small over time.
Adam stands for adaptive moment estimation, and is another way of using past gradients to calculate current gradients. Adam also utilizes the concept of momentum by adding fractions of previous gradients to the current one. This optimizer has become pretty widespread, and is practically accepted for use in training neural nets.
32. Which method is not used to suppress overfitting?
1) normalization 2) regularization 3) data augmentation 4) backpropagation
As we know, overfitting is a problem that we encounter frequently in machine learning.
Dropout techniques together with L1/L2 regularization are known regularization techniques to reduce overfitting. They will discourage test data memorization in neural networks.
Data augmentation is another common way to face the overfitting problem. Basically this means we create some new input data that we know will increase the quality of the training data.
Normalization would be to normalize the input data and would also assume batch normalization techniques inside the NN.
The backpropagation is an algorithm used to find a local minimum of the error function, not a technique to suppress overfitting.
33. Regularization will make your model:
1) simpler 2) complex
Regularization refers to a broad range of techniques for artificially forcing your model to be simpler.
For example, you could prune a decision tree, use dropout on a neural network, or add a penalty parameter to the cost function in regression.
Oftentimes, the regularization method is a hyperparameter as well, which means it can be tuned through cross-validation.
34. Convolution filters reduce memory needed to train the model?
1) True 2) False
Without convolution, a machine learning algorithm would have to learn a separate weight for every cell in a large tensor.
For example, a machine learning algorithm training on $2K \cdot 2K$ images would be forced to find 4M separate weights.
Thanks to convolution, a machine learning algorithm only has to find weights for every cell in the convolutional filter, dramatically reducing the memory needed to train the model.
35. Those are parameters that are used to configure a convolution layer. Which one is used to set how many pixels the kernel windows will slide.
1) Kernel size (K) 2) Stride (S) 3) Zero Padding (pad) 4) Number of filters (F)
Stride shows how many pixels the kernel window will slide. Normally 1, and 2 on pooling layers.
Kernel size refers to the width and height of the filter mask. Zero Padding puts zeros on the image border to allow the conv output size be the same as the input size.
Number of filters (F) is the number of patterns that the conv layer will learn.
36. Hidden Markov Model (HMMs) is used often for?
1) speech recognition 2) non sequence modeling
Hidden Markov Models are a tool for modelling sequence behaviour.
They are used in speech recognition systems.
37. Your targets are one-hot encoded. Which loss function would you choose?
1) sparse categorical entropy 2) categorical cross entropy
A one-hot encoding is a representation of categorical variables as binary vectors.
For instance: (cat, dog) as [1,0], [0,1].
You should use categorical cross entropy in this case. When your targets are integers you can use sparse categorical entropy.
38. What is an agent in artificial intelligence?
1) a person 2) a robot 3) anything equipped with sensors that can act
Anything that perceives its environment by sensors and acts upon an environment by effectors are known as Agent. Agents include robots, humans and programs.
Agents are well known term in one particular machine learning branch called reinforcement learning.
39. We update the weights of our NN directly based on the:
1) loss function 2) optimizer function
The optimizer is how the model is updated based on the data it sees and its loss function. One famous optimizer is the SGD optimizer.
Loss function measures how accurate the model is during training. We want to minimize this function to “steer “ the model in the right direction.
Use metrics to monitor the training and testing steps.
40. What is the name of the object in Google TensorFlow that encapsulates the environment in which operation objects are executed?
1) placeholder 2) graph 3) session
A Session object encapsulates the environment in which operation objects are executed, and Tensor objects are evaluated.
TensorFlow uses a dataflow graph to represent your computation in terms of the dependencies between individual operations. This leads to a low-level programming model in which you first define the dataflow graph, then create a TensorFlow session to run parts of the graph across a set of local and remote devices.
Higher-level TensorFlow APIs such as tf.estimator and Keras hide the details of graphs and sessions from the end user.
41. Keras is an open source neural network library written in?
1) C++ 2) Python 3) R
Keras is a high-level neural networks API, written in Python. It was developed with a focus on enabling fast experimentation.
It is capable of running on top of TensorFlow, Microsoft Cognitive Toolkit, or Theano. Designed to enable fast experimentation with deep neural networks, it focuses on being user-friendly, modular, and extensible.
42. What does Keras mean?
1) horn 2) elephant tusks
Keras (κέρας) means horn in Greek. It is a reference to a literary image from ancient Greek and Latin literature, first found in the Odyssey, where dream spirits are divided between those who deceive men with false visions, who arrive to Earth through a gate of ivory, and those who announce a future that will come to pass, who arrive through a gate of horn.
43. Pandas is a column-oriented data analysis API. The primary data structures in pandas are DataFrame and Series. Which one represents a column?
1) DataFrame 2) Series
Pandas is a great tool for handling and analyzing input data, and many ML frameworks support pandas data structures as inputs.
DataFrame represents a relational data table, with rows and named columns. Series represents a single column. A DataFrame contains one or more Series (features).
44. In TensorFlow using tf.estimator dramatically lowers the number of lines of code?
1) True 2) False
In TensorFlow you can use lower-level APIs to build models by defining a series of mathematical operations.
Alternatively, you can use higher-level APIs (like tf.estimator) to specify predefined architectures, such as linear regressors or neural networks.
This way tf.estimator dramatically lowers the number of lines of code compared to the lower-level API.
45. When Ai system performs as high-human this means it performs:
1) better than all humans 2) better than most humans 3) similarly to most humans 4) worse than most humans
Here is the definition of terms:
super-human: performs better than all humans
high-human: performs better than most humans
par-human: performs similarly to most humans
sub-human: performs worse than most humans
46. What is R-CNN?
1) recursive convolutional neural network 2) region convolutional neural network
CNN stands for convolutional neural network and they are used for image classification. While R-CNN, with the R standing for region, also detects the 2D frame (region) of the object from the image.
A classic CNN can only tell you the class of the objects from the image but not the object location.
The regions in the R-CNN are detected by selective search algorithm followed by resizing so that the regions are of equal size before they are fed to a CNN for classification and bounding box regression.
47. Generative adversarial networks (GANs) are close to something called “machine dreaming “?
1) True 2) False
Generative Adversarial Networks (GANs) are a class of Ai systems implemented by a system of two NN working in parallel.
First NN generates photos that look at least superficially authentic to human observers. Second NN evaluates the quality of photographs helping first NN to improve. This feedback will likely achieve what is called “machine dreaming”.
48. Which one is fastest NN recognizing 2D objects regions?
1) VGG16 2) YOLO 3) R-CNN 4) Fast R-CNN
The YOLO (You Only Look Once) model has several advantages over classifier-based systems.
It looks at the whole image at a time and makes predictions with a single network evaluation unlike R-CNN which requires thousands of predictions for a single image. This makes it extremely fast, more than 1000x faster than R-CNN and 100x faster than Fast R-CNN.
VGG16 (also called OxfordNet) is a convolutional neural network architecture named after the Visual Geometry Group from Oxford, who developed it. It was used to win the ILSVRC (ImageNet) competition in 2014. It doesn’t detect object regions.
49. Can AI create music?
1) True 2) False
Several music softwares (such as magenta) have been developed to produce Ai music. AI algorithms will listen to music and produce new music based on what it learned.
Artificial intelligence also drives the so-called interactive composition technology, where a computer composes music in response to the performance of a live musician.
50. Find the intruder:
1) beauty detection 2) image tagging 3) sales prediction 4) natural language processing
Ai can handle many tasks wery well such as: natural language processing, sales prediction, self-driving cars, facial expression recognition, image tagging, and many more…
However, beauty is not an observable (quantifiable) metric. The best we can do is search for observable proxy metrics for beauty.
Additional material
What is regularization?
Regularization is a process to escape from overfitting. There is always a trade in machine learning when we learn from our training dataset.
We do want to learn from a training dataset, but we would like to generalize so that our knowledge is not specific for our training dataset.
We do want to learn from a training dataset, but we don’t want to learn exactly it – instead we would like to get the general rules.
If validation loss is the loss is of our validation dataset, and our training loss is the loss of our training dataset then:
If validation loss » training loss you can call it overfitting.
If validation loss > training loss you can call it some overfitting.
If validation loss < training loss you can call it some underfitting.
If validation loss « training loss you can call it underfitting.
We have exactly the next three cases:
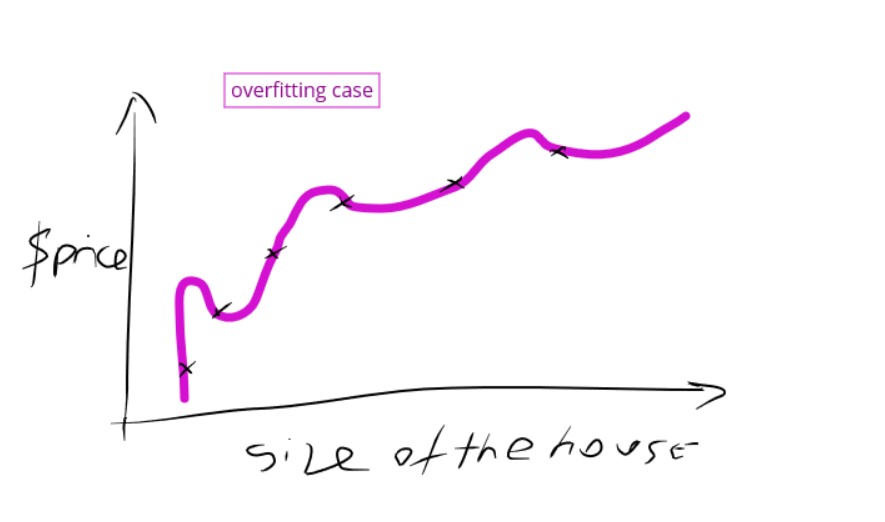 Legend: Overfitting case
Legend: Overfitting case
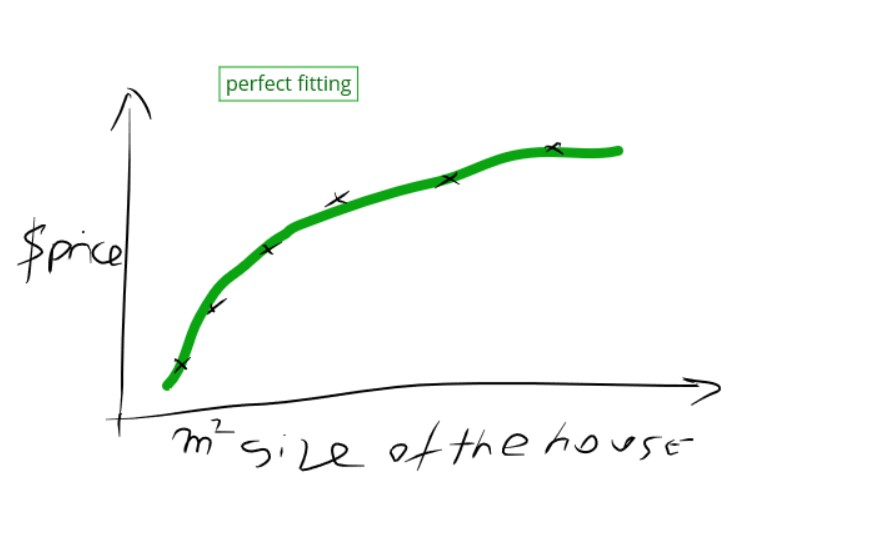 Legend: Perfect fitting case
Legend: Perfect fitting case
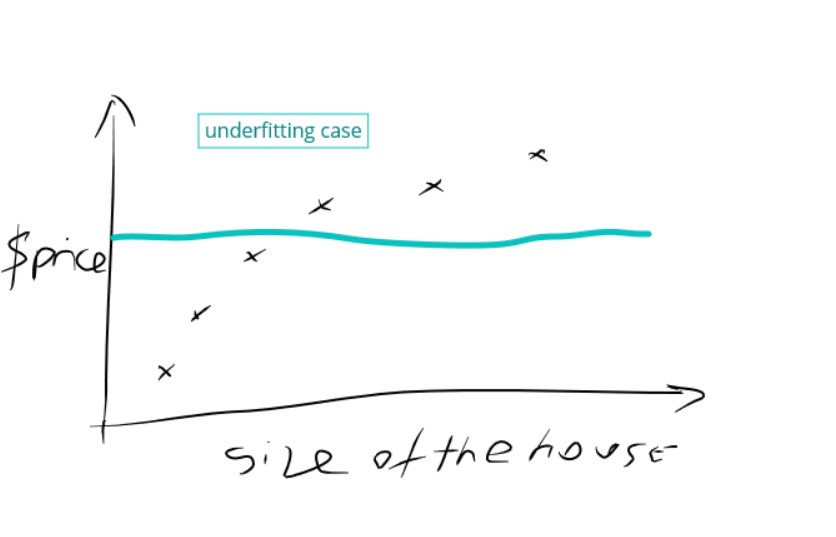 Legend: Underfitting case
Legend: Underfitting case
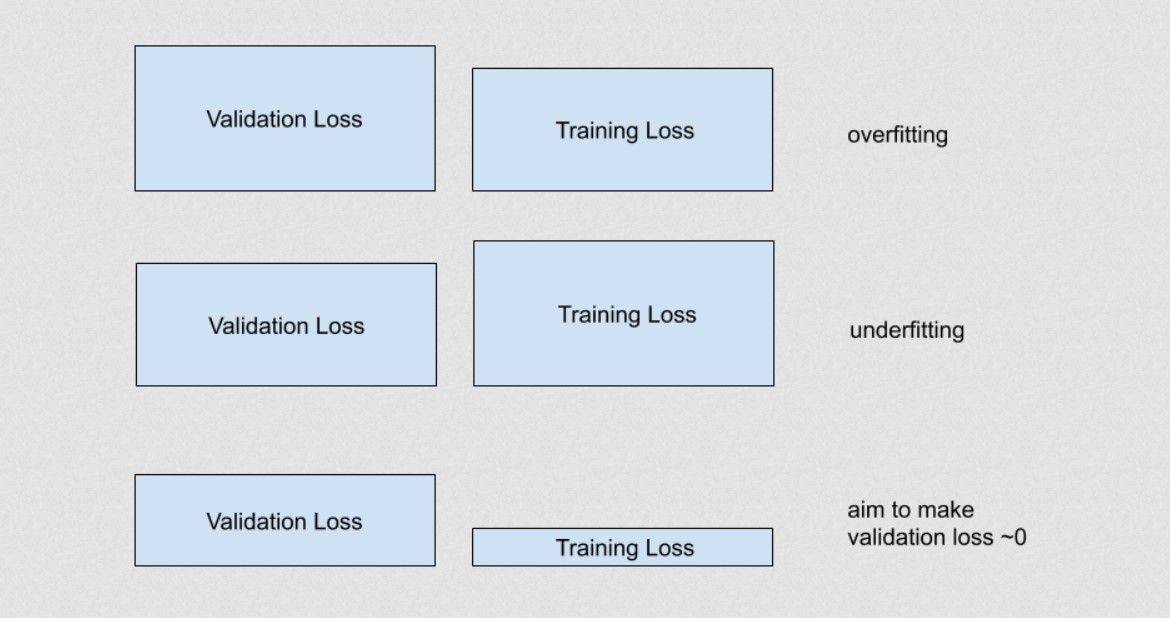
Legend: validation vs. training loss
There is a scalar parameter $\lambda$ called regularization parameter (rate).
\[\text{minimize(Loss(Data|Model)} + \lambda \text{ complexity(Model))}\]The goal is to select the right $\lambda$ value:
If the $\lambda$ value is too high, your model will be simple, but you run the risk of underfitting your data. Your model won’t learn enough about the training data to make useful predictions.
If the $\lambda$ value is too low, your model will be more complex, and you run the risk of overfitting your data. Your model will learn too much about the particularities of the training data, and won’t be able to generalize to new data.
With the right $\lambda$ we will be able to learn but still enable our machine learning process to generalize well.
L1 vs. L2 regularization
Least absolute deviations(L1) and Least square errors(L2) are the two standard loss functions.
Both are almost always used for regression to minimize the error.
L1 Loss function stands for Least Absolute Deviations (LAD).
L2 Loss function stands for Least Square Errors (LS)
We can express the L1 and L2 corresponding errors as:
MAE (mean absolute error) formula would be:
\[MAE = \frac{1}{N} \sum_{(x,y)\in D} |\ {y - prediction(x)\ |}\]MSE (means squared error) formula:
\[MSE = \frac{1}{N} \sum_{(x,y)\in D} (y - prediction(x))^2\]where $N$ is the number of elements or $x,y$ pairs.
Loss functions used for regression vs. loss functions for classification
Classification:
- Log Loss
- Focal Loss
- KL Divergence (Relative Entropy)
- Exponential Loss
- Hinge Loss
Regression
- Mean Square Error (Quadratic Loss)
- Mean Absolute Error
- Huber Loss (Smooth Mean Absolute Error)
- Log cosh Loss
- Quantile Loss
Machine learning types
Supervised learning
- Linear Regression
- Logistic Regression
- Decision Trees
- Random Forest
- Gradient Boosted Trees
- Support Vector Machines (SVM)
- Naive Bayes
- Nearest Neighbors
Unsupervised learning
- Clustering
- Dimensionality reduction
Semi-supervised learning
- Continuity assumption
- Cluster assumption
- Manifold assumption
- Generative models
- Low-density separation
- Graph-based methods
- Heuristic approaches (self-labeling)
Reinforcement learning
- Q-Learning
- Temporal Difference (TD)
- Monte-Carlo Tree Search (MCTS)
- Asynchronous Actor-Critic Agents (A3C)
Linear regression
With linear regression we are trying to solve the problem of fitting scattered points to a line.
This is why we need a line:
$y = ax + b$
where:
$a$ is the slope of the line, and $b$ is the y-intercept.
In machine learning, we use weights and biases so:
$y’ = w_1x_1 + b$
or in general case:
$y’ = Wx$
where:
$y’$ is the predicted label (a desired output). $b$ is the bias (the y-intercept), sometimes referred to as $w_0$.
$w_1$ is the weight of feature 1. Weight is the same concept as the “slope” $a$ in the traditional equation of a line.
$x_1$ is a feature (a known input), and $\bf W$ and $\bf B$ are vector representations for weights and bias if we generalize.
General model on three features might look as follows:
$y’ = b + w_1x_1 + w_2x_2 + w_3x_3$
Having multiple features we can say we have multiple regression cases.
Logistic regression?
With logistic regression we are trying to predict True or False, or 0 and 1. If we would use linear regression for the same we would possibly end with probabilities less or greater than 1, and less and greater than 0.
So we need a special loss function for logistic regression:
$Log Loss=\sum_{x,y \in D} -y \cdot log \ y’ -(1-y) \cdot log(1-y’)$ or $Log Loss=- \frac{1}{N} \sum_{i=1}^N y_{i} \log \, p_{i} + (1 - y_{i}) \log \, (1 - p_{i}).$
where $y’_i=p(y_i)=p_i$
Log Loss (related to cross-entropy) measures the performance of a classification model where the prediction input is a probability value between 0 and 1.
What is information?
Information quantifies the uncertainty in one single event. Claude Shannon
To define these words we use the following math:
$I(x) = -log_₂P(x)$
Here $P(x)$ is the probability of occurrence of $x$.
If $P(x)=1$, then $log_₂1=0$, so no information.
If $P(x)=0.5$, then $log_₂0.5=-1$, so $I(x)=1$.
If $P(x)=\frac 16$, then $log_₂\frac 16=-2.589$, so $I(x)=2.589$.
Last formula may provide information rolling a die and getting a single value i.e. 6.
It is expressed in bits. So you would actually need 3 bits to save this information.
The more uncertain the event is the more information we get.
NLP core labeling tasks
There are 8 core NLP labeling tasks:
- POS Part-of-speech tagging is the syntactic task of assigning tags such as noun, verb, adjective, etc. to individual tokens.
- Constituent labeling assigning a non-terminal label for a span of tokens within the phrase-structure of the sentence: e.g. the span a noun phrase, or verb phrase, etc.
- Dependency labeling seeks to predict the functional relationships of one token relative to another: e.g. subject to object relationship.
- Named entity labeling is the task of predicting the category of an entity referred to by a given span, e.g. does the entity refer to a person, a location, an organization, etc.
- Semantic role labeling (SRL) is the task of defining subject-predicate relation: e.g. given a sentence like “Bob drinks water”, SRL will define Bob as the actor.
- Coreference is the task of determining whether two spans of tokens refer to the same entity (or event): e.g. do “Alexander Lukashenko” and “the current president” refer to the same person.
- Semantic proto-role (SPR) labeling is the task of annotating fine-grained, non-exclusive semantic attributes, such as change of state or awareness, over predicate-argument pairs. E.g. “Bob drinks water”; SRL is concerned with identifying if Bob is aware of what he is drinking.
- Relation Classification (Rel.) is the task of predicting the real-world relation that holds between two entities, typically given an inventory of symbolic relation types (often from an ontology or database schema). For example, given a sentence like “Bob is going home”, relation classification is concerned with linking “Bob” to “home” via the Entity-Destination relation.
…
tags: questions - statistics - probability - theory & category: machine-learning